
Today, we are going to look at the demo standard deviation charts that come with the internal developer VM OBIEE 11.1.1.6.2. We’ll look at several misleading statistics that are produced with this report and suggest ways to make the page more understandable for the user. Below is the page (1) that we will be investigating.

(1) Standard Deviation Page
Start with the upper left graph (2), it appears to be using confidence bands on the different factors. One can think of a confidence band as a continuous confidence interval for a linear model. This data is not continuous but consists of factors consisting of several different levels; these levels are independent of each other and should be considered separately. Having continuous lines between Audio and Portable would indicate to me that there are possible values between them but there are not. The mean and median calculations are important to this graph and should be kept in; the mean is actually the best statistic represented because there are points for each mean and they are connected by a light line.
Next, let us consider what “Avg+SD” and “Avg-SD” really mean. This is the basic construction for a confidence interval and if the data is Normally Distributed we would have a 68% confidence interval, the only statement we can make is “we are 68% confident that the population mean is between ‘Avg+SD’ and ‘Avg-SD’.” We need to make this statement because the mean is a fixed constant and not a random variable; this is a frequentist belief in statistics.
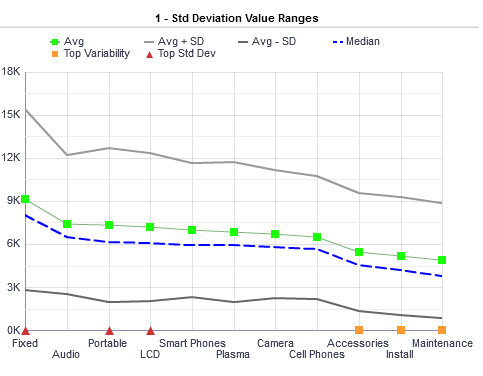
(2) Standard Deviations Value Ranges Graph
The next issue with this dashboard is the second graph (3):
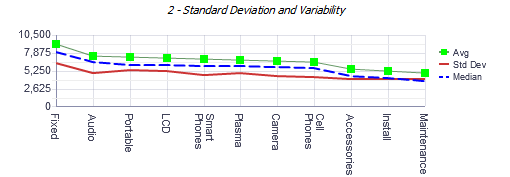
(3) Graph of measures of center and Standard deviation.
Again, the lines appear to be continuous (except the calculation of the means) but we have addressed this issue in the prior section. I feel that this is useful to see the mean, median, and standard deviation. If the mean is equal to the median we can say that the distribution is symmetric but in practice this is very rare and we should be happy to see that they are close to each other (as in this example). The y-axis on this is labeled somewhat unconventionally using 2,625 as the markers, this is a preference but I prefer the vertical axis to be rounder numbers and in this graph I’d consider (3,000; 6,000; 9,000; 12,000) for the scale. This graph is helpful for the user because they will be able to see the magnitude of the standard deviation in relation to the mean and median.
The summary statistics table (4) is one of the most important objects on this dashboard and the most useful for the user to see:
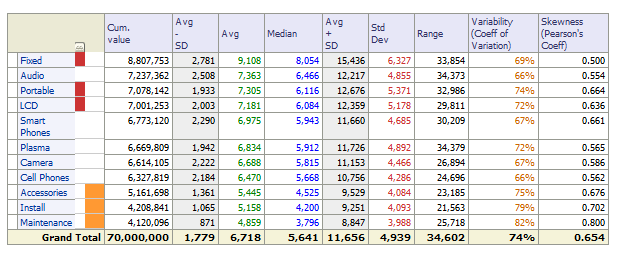
(4) Summary Statistics Table
All of the columns are very useful; the coefficient of variation is one of the best ways to compare standard deviations because there is no unit of measurement associated with that ratio, but if the mean is close to zero the ratio will approach infinity (this is not a good thing). Pearson’s Skewness Coefficient, which is simply a multiple of a non-parametric skew, is a very common measure for skewness. Skewness measures the extent to which data deviate positively or negatively from symmetry, if the computed value is greater than 1 (less than -1) denotes a strong positive (negative) skew. It would also be nice if the first and third quartiles were added near the median or range.
Presenting statistics to an audience is a delicate practice; you want to produce a clean and concise picture of what you’re interested in. It is easy to produce graphs and numbers that are not useful and will only lead to confusion. People need to be able to look at a report and be able to clearly and quickly understand what is being presented. When working with statistics and visualizations, the developer must remember Occam’s Razor, the simpler explanation should be preferred.