Visualizing data has always been valuable, but in the ever growing world of “big data”, it is necessary for visualizations to be both aesthetically pleasing and easy to understand. Today, it is common to see visualizations that — though they “look good from a distance” — are entirely too complicated and leave the audience confused once they actually begin trying understand the information presented.
More important than how it looks from a distance, it is critical for a user to look at the visualization and be able to understand the message quickly. As implementers of business intelligence solutions, we often discuss the characteristics of our user audience, typically an audience that wants to spend the least amount of time possible to understand information.
All too often, we see organizations and implementers make the mistake of leaning too far on the side of looking good from a distance, at the severe expense of processing efficiency and understandability.
As we do our part to make the data visualization world a better place, we have planned a series of articles identifying these examples and calling out issues we see to spark discussion. Today, we will start the series with a post from Information is Beautiful, where they have created a visualization about punitive damages incurred by large corporations. We initially looked at this visualization as a positive way to represent data creatively (and we do sincerely thank the author/publisher for thinking outside the box since this is exactly the kind of attempt that will move the data visualization world forward), but our discussion quickly turned into a productive argument about the true value of this visualization.
Before we begin our discussion, our team would like to thank David McCandless and his team for all of their investigative work to collect the data, standardizing it to one spreadsheet and making it easily available for other readers. This will allow others to freely reproduce his findings in ways they deem fit.
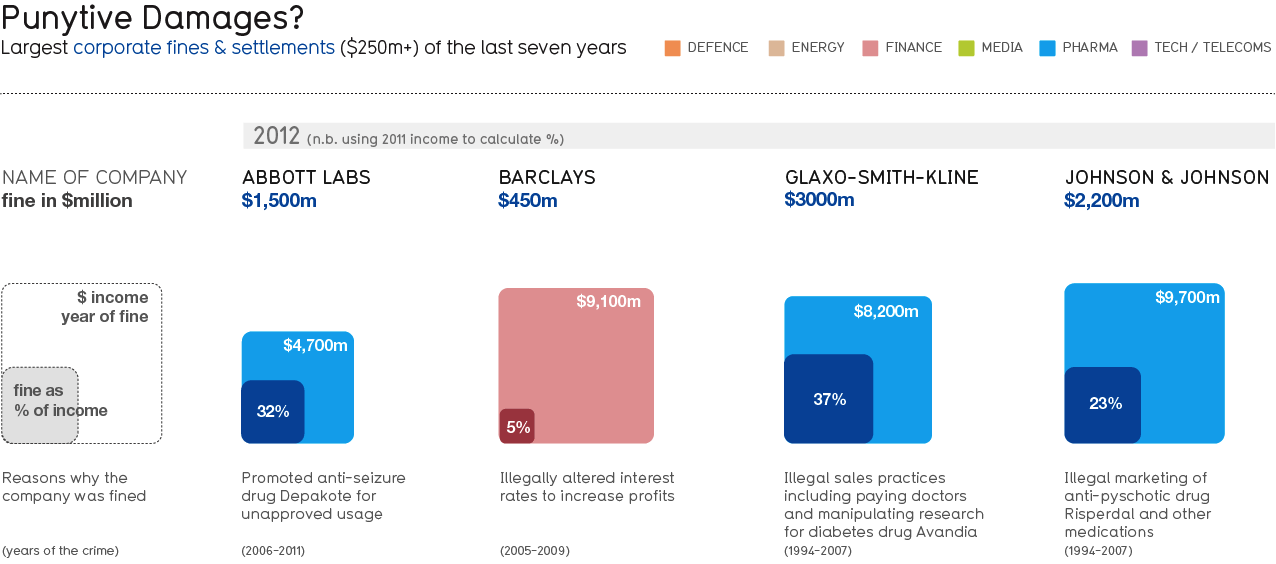
Aesthetically, this certainly looks good from a distance. It is minimalistic while appearing to present some potentially useful information. But as a few of us at M&S have analyzed and argued, we believe there are serious flaws with this visualization.
We felt these less-than-optimal choices:
- Choosing two-dimensional (2D) shapes instead of one-dimensional (1D) representations for data values
- Why did the punitive damages only go back to 2005?
- Leaving out the y-axis
- Suboptimal use of colors
- Suboptimal use of whitespace
resulted in the following outcomes:
- Hard to compare income between companies
- Hard to compare fines between companies
- Hard to understand magnitude of fine relative to income (yes, although this was likely the author’s main goal to make even more understandable, it has actually become even harder!)
- Hard to compare results of Year X compares to Year Y
- Hard to read values in some cases
- Other more minor and tangential issues arise as well
To start, it is not intuitive to visualize the difference between two squares, especially when represented as a two-dimensional object. In fact, this was discussed in more detail in Darrell Huff’s book Lying with Statistics which was released back in 1954. Dimensionality in general is a difficult concept to grasp.
For example, the fact that Barclays income is almost double that of Abbott Labs is not something most people envision in their minds as two-dimensional representations. One would normally see a y-axis value about double-the-height in a bar or line chart, but when respecting a two-dimensional space as the author has done here, double-the-income does not at all equate to double-the-height. Hence, it is no surprise the author did not include a y-axis in this visualization (which we feel is another flaw and have addressed later in this article).
To be clear, the issue here is not about the use of squares as the object shape specifically, but the use of a two-dimensional object at all. In other words, we would have the same argument if the author used circles instead of squares. In fact, when we go to get a medium vs. large pizza, we sometimes have a hard time realizing how much bigger the large really is over the medium.
Since we are so accustomed to looking at this kind of data in one-dimensional bars/lines, our minds can be confused when processing so many aspects of this two-dimensional object. As another example, trying to visualize a percentage inside of a two dimensional object also is not intuitive. We are only looking at income and the percentage of fines relative to income, so trying to make this into two dimensions seems cumbersome when there are obvious 1D choices like bars (or even stacked bars). To drive home this point, one of us asked the other to draw square A and then draw square B 20% of square A inside of it. This proved to be much more difficult to perform than drawing line A and then drawing line B 20% of line A either inside (aka stacked bar) or next to it (two bars). By the way, after performing this exercise, we have all vowed to begin ordering medium pizzas, and sticking only with circular ones!
While our team was reviewing the data and considering our own rendition of this visualization, we noticed that the years only went back to 2005. We noticed 3 companies who had a negative income compared to their fines (QWest, Schering-Plough, and Worldcom) and they were all before 2005. One reason why these may have been left out was because you cannot easily visualize a negative area as a square. The biggest drawback from two dimensions vs. one is that we lost a lot of valuable information, 12 fines that were not reported because of these three companies. This loss of information devalues the entire point of presenting data in this type of manner. One dimension is honestly the only way to go in this type of situation.
Our final issue with this graphic was the horizontal space used by both the 1) large two-dimensional square shapes as well as the 2) white-space between the companies. It would have been nice to see the layout of this visualization in a horizontal manner, which — combined with a 1D choice instead of 2D — would have made it easy for the user to compare across companies and even across years. Again, it looks nice from afar and we aren’t taking that away, but it is a somewhat wasteful use of space that should be considered when presenting data for an audience hungry to understand quickly and find their own patterns/conclusions.
All of the arguments we have presented above are major flaws with this visualization. And the author really helps us make our points with his visualization in 2005.

- If we compare Enron and Serono Labs, we can easily see that Enron’s fine was roughly double the fine of Serono Labs, but the squares do not appear to be representative of that difference. Also, it is not clear what the Enron fine or income is until you actually read the fine print below – and it is still unclear what data value(s) the Enron brown square represents.
- Now let’s look at Bank of America and Samsung. Their income is quite different and their fines are only a small percentage of the income (4% and 3% respectively), but the size of Samsung’s 3% fine square seemed odd relative to Samsung’s income square, especially when we compared to the size of BofA’s 4% fine square. Here we have a case where the Samsung fine is less than half that of BofA, however, the fine square for Samsung is larger which can be extremely confusing.
- Time Warner and Serono Labs had fines that exceeded their income. It is very confusing to change the shading of the income and the fines. It is also confusing to change the location of the printed values (in all other cases, the income value was top-right of the fine percentage and we had to think a little harder than we should have been required to determine what was going on here). Not to mention that it is very hard to read white text on the light yellow-green background in the case of Serono Labs. Keeping the coloring more consistent and possibly making use of color transparency/patterns so it shows through the darker areas could have really helped.
We feel it is important to call out these observations because one of the most common ways people get deceived is not by raw data itself, but by the visualizations of data. We have picked one visualization today, but there are many out there, and certainly ones that we have created as well. We truly hope this has helped you add to your toolbox and thought process while creating and analyzing data visualizations.
Note, we considered creating our own data visualization that avoided the concerns we have with the current visualization, but we wanted to focus on the concepts rather than focusing on this data, and we would need to plan the time it would take to create a thoughtful, “competing” visualization. It is worth mentioning again that we commend the journalistic work of the author and the visualization creativity explored; it is not our goal here to “compete” but instead to open discussions.
[box]We are interested in hearing feedback on our assessment of this visualization as well as the general concepts we have brought up (e.g. the use of 2D shapes being potentially more confusing than 1D shapes). Also, if you have seen other disorienting data visualizations, please feel free to share as we prepare our next article in this series.[/box]
4 Comments on “Disorienting Data Visualizations”
I think 2D representation was quite appropriate, as I assume the primary objective was to compare the size of fine across industries and across two different time periods.
The graphic could have been enhanced and improve with both datasets on the same page, for easy comparison and I agree the accruate proportionality.
Thank you for commenting Joseph. You mention that 2D was appropriate but then mention concerns about the accuracy of the proportionality. I think the issue you may have had with the proportionality was perhaps related to the shape being 2D.
Thank you for this thoughtful and timely article! I find your argument very compelling. Perhaps the only way it could have been more persuasive would be if it were rendered as a two-dimensional object. (Just kidding, of course.) I found your observations to be readily understood and your position well-framed. Indeed, one overarching principle for such visualizations should be: “Never make your graphic more complex than the data it represents. Always select the simplest, most communicative option.” By using boxes rather than lines or bars (which are also two dimensional, btw), the means for comparison are stymied. Ultimately, the author of the graphic must have in mind what question(s) he wishes to address. Comparing companies is an obvious but, in this case, difficult option.
Thanks again for this thoughtful article!
We’re very glad you found the article useful and easy to follow. Thank you for taking the time to comment.
By the way, you mentioned: “By using boxes rather than lines or bars (which are also two dimensional, btw), the means for comparison are stymied.”
I assume we are on the same page, but to clarify, we are distinguishing the fact that the boxes represented the y-value in two dimensions, while a line or bar would represent the y-value in one dimension.